
Disclaimer: Sorry, another nerd post.
One of my personal projects recently has been replacing my Cacti setup. I realized I had been moving computer systems around and hadn’t updated the graphing system that monitored them over time, so I figured it was about time to overhaul.
The actual replacement system was pretty easy. I’ve rolled out Cacti several times, and this wasn’t much different. Learning from the past mistakes helped me utilize templates much more efficiently, the only thing I’m really lacking at this point is the ability to monitor a handful of devices on my network.
The other thing I’ve been eyeing for a while is a tool called “Network Weathermap” – I’ve been trying to push for us to build weathermaps for at least the larger market presences we have at work, either as a marketing tool or just to help diagnose high network traffic issues quickly. I showed it to my boss and he was impressed, but I wanted to actually make it work so that I had some idea of what kind of work would be involved. This is my network: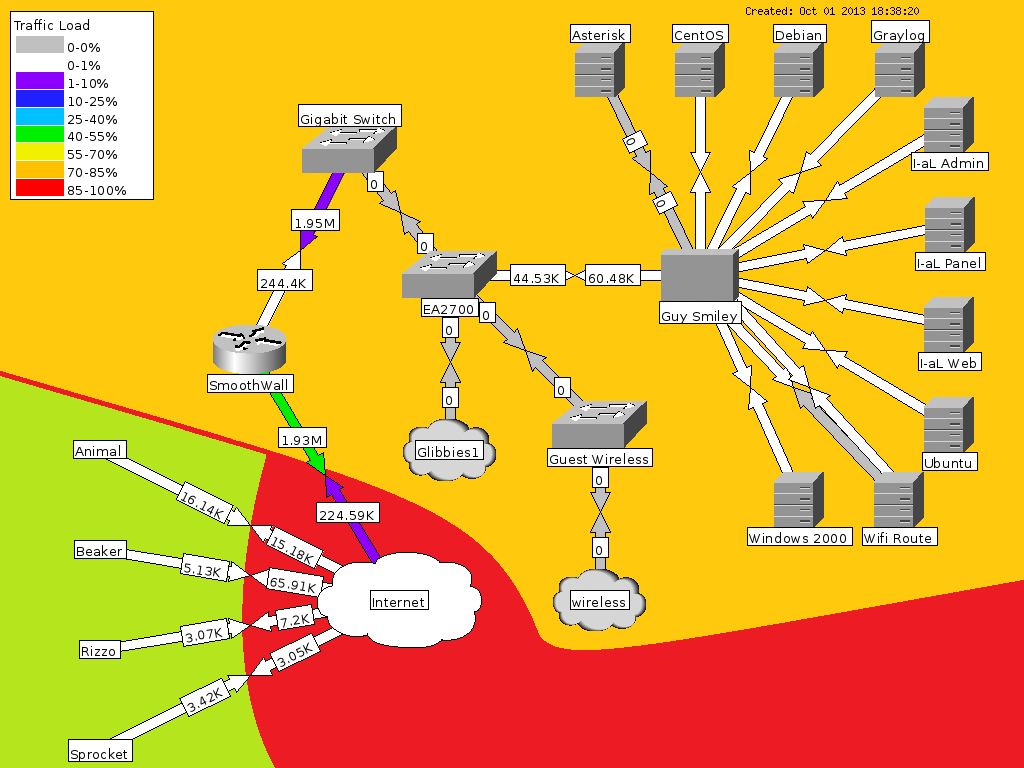
You see the green section, those are virtual servers represented individually. My home network is in the orange. Physical links (or virtual physical links) are shown, unfortunately I don’t have the ability to monitor any of my switches. The one I might be able to is the Guest Wireless switch but it’s locked down too tightly. But that’s a problem I can solve later. Guy Smiley is my VMWare server, the other machines are all guests on that server.
I’m actually slightly disappointed at how boring it is!
That said, as a brief review of Network Weathermap, it’s a pretty awesome tool. It’s fairly picky about how it is set up, and the WYSIWIG editor that comes with it needs a lot of work (which it freely admits). That said, getting all the nodes placed was simple. Getting the links configured was also pretty easy (it’s just a case of linking nodes the right way round for the Cacti graphs, and if you get it wrong, editing the config file is simple). The thing that took the longest time was getting everything aligned to my liking. The WYSIWIG editor wouldn’t let me select more than one node and move groups of nodes together.
If you’re a nerd with a monitorable network like me, give it a try!



